

The holy grail for any product is low marginal cost and high value. That is why, over the past two decades, software has crept its way into nearly every part of our lives and, for all intents and purposes, eaten the world. I have a strong hunch that genetic testing is going to eat the world in a similar fashion.
This is because the cost of sequencing has dropped to a mere pittance if you consider that 20 years ago the price tag for DNA sequencing was north of $100 million but now sits closer to the $200-$1000 range. What a win for Moores law!
And now, with the latest advances in biology, we’re closing in on a future where genetic testing will help pharma companies identify patients more likely to respond to a drug, giving them ammo to win market share in crowded drug categories.
With the stakes so high, companies are chasing these outcomes in the billion dollar GLP-1 market, trying to figure out whether their genetic models can determine which GLP-1 someone should take, predict how much weight they might lose, whether they experience side effects and what happens after treatment stops.
How close are we to this future? That’s what I wanted to find out, so I spoke with Adam Auton, Vice President of Human Genetics at 23andMe and an author of a first-of-its-kind paper on the genetic predictors of GLP-1 response.
This post is a thorough explanation of the research Adam and his team have done and where we think the commercial value will emerge.
1. Your DNA Can Reveal One Version of Your Future
Our DNA contains roughly three billion nucelotides made up of four bases: A, C, G and T. Groups of these letters provide the instructions for amino acids, which are assembled into proteins. At certain positions, one person might carry a T while another carries an A. This one-letter difference is called a genetic variant, which could alter an amino acid that makes no difference at all or very slightly change how a protein or receptor functions.
Geneticists are tracking how these variations lead to different weight-loss responses to GLP-1s and whether someone is more or less likely to experience side effects.
Since we inherit one copy of our DNA from each parent, a person can carry zero, one, or two copies of a particular variant. At one position, for example, someone might have TT, TA, or AA. Researchers then compare these three variants across a large population. If people with AA and AT have a slightly higher average BMI than those with TT, having an A base in that position becomes associated with higher BMI.
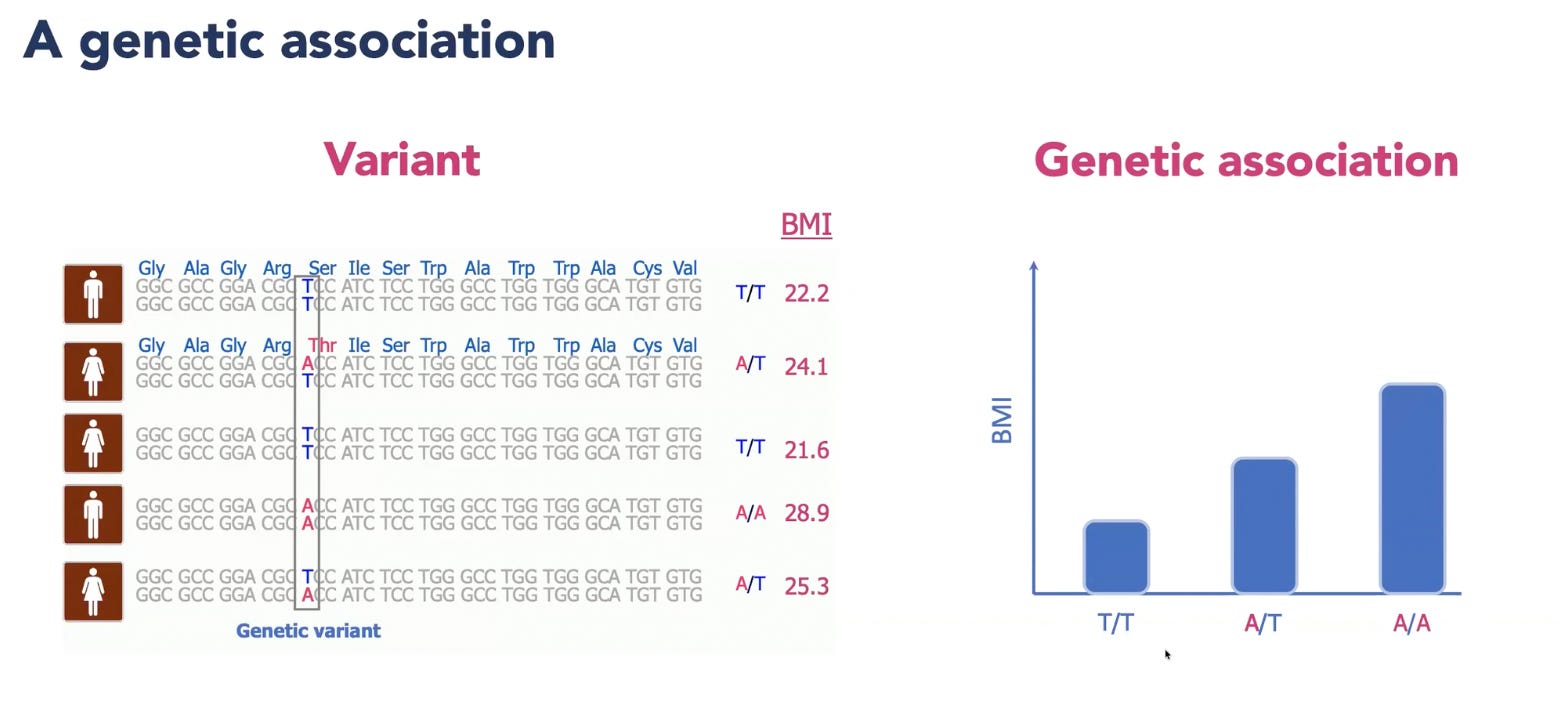
To build a BMI Polygenic Risk Score (PRS), researchers combine millions of variants associated with BMI. They count how many copies of each variant a person carries and weigh each one according to the strength and direction of its association with BMI. These weighted effects are then added together to produce an overall individual score.
When you look at the population level, BMI Polygenic Risk Scores are normally distributed, meaning most people cluster around the middle while a much smaller number sit at either extreme (the tails).
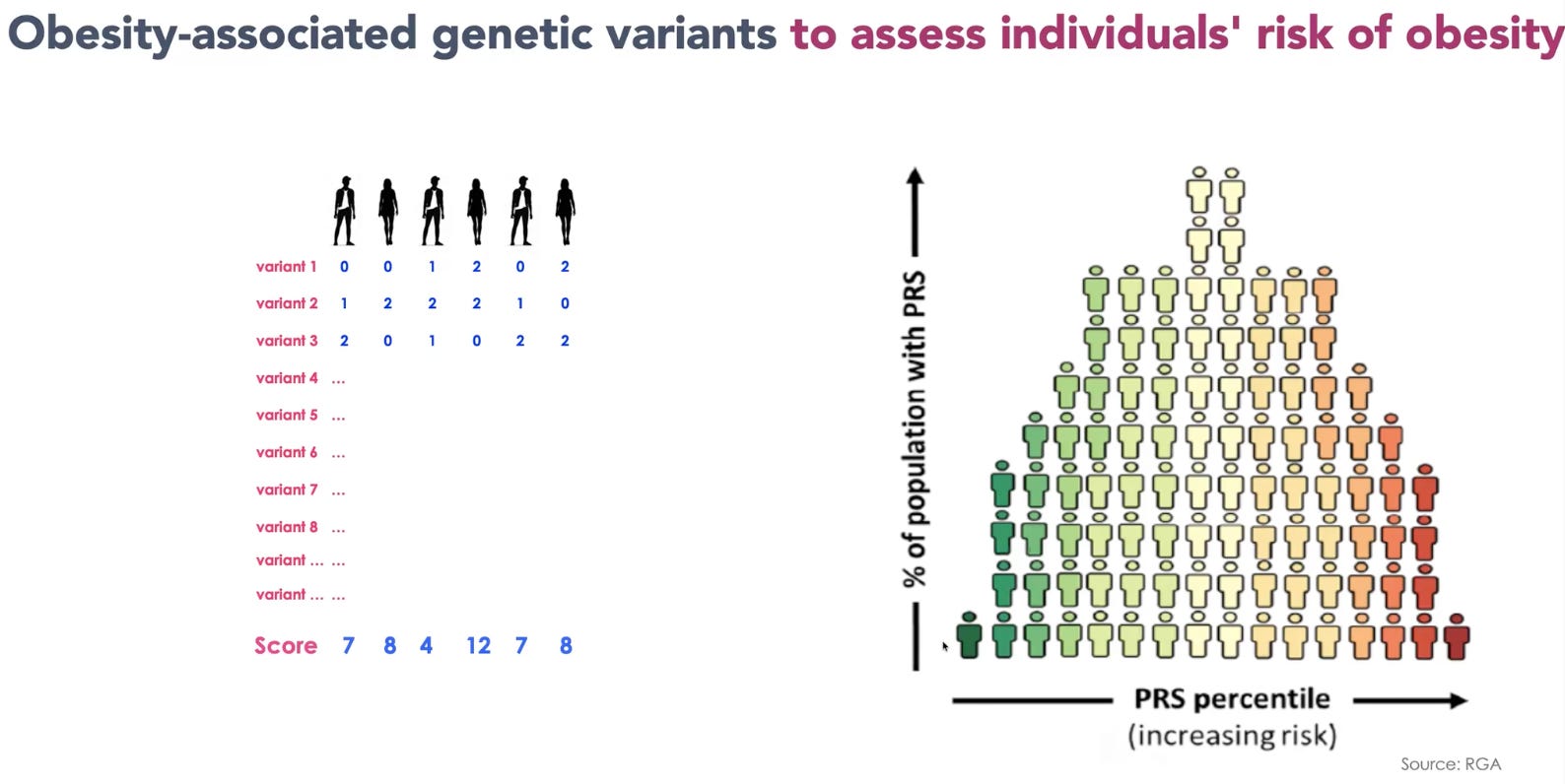
With the advent of larger data sets, Polygenic Risk Scores are getting better and better, particularly at identifying people at the extremes.
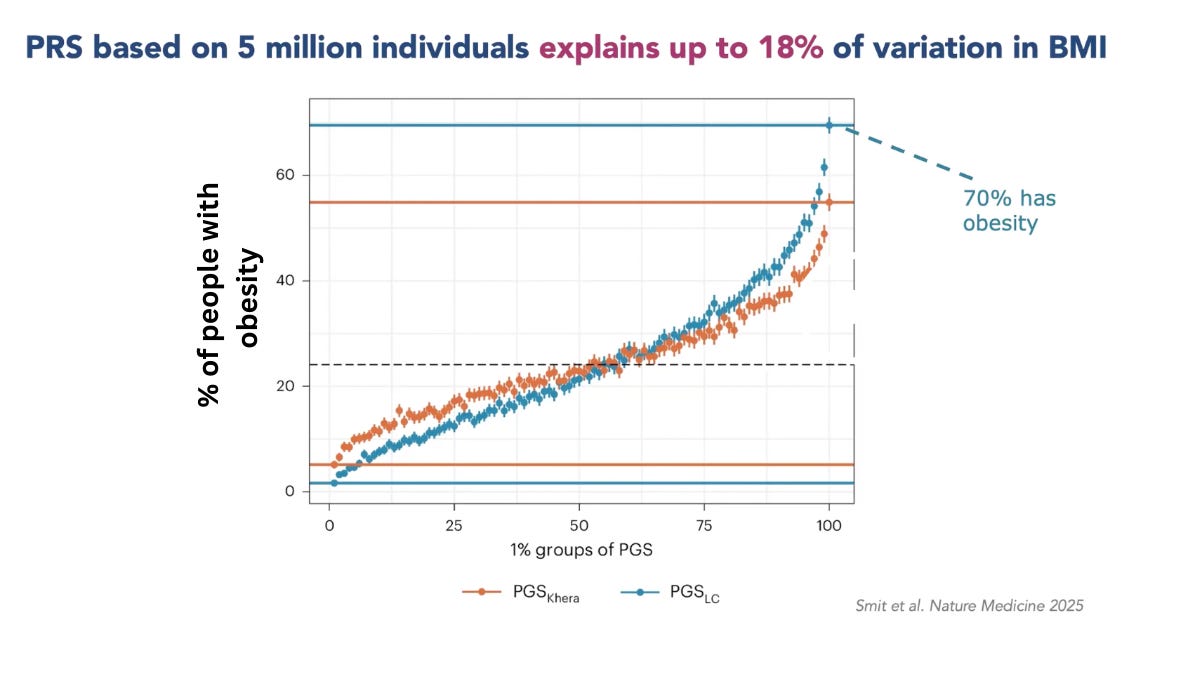
In the chart above, you can see that among people scoring in the top 1% of this BMI Polygenic Score (PGS) almost 70% had obesity! I find this result so mind-bogglingly crazy because we’re inching toward a world where, by looking at someone’s DNA, we can infer one possible version of their future. It feels like something out of Vanilla Sky or Gattaca. The optimistic scenario is that we could identify people with unusually high genetic susceptibility to obesity during childhood, and intervene before obesity takes hold and its complications develop.
The problem is that the same information could create a pit of despair and fatalism. If you tell someone that they sit in the highest 1% for genetic susceptibility to obesity, they may not hear “You have an opportunity to act early” but rather “Your future has already been decided, so there’s no point in trying.” This was one of my concerns when speaking to Adam, because people perceive agency differently, but his response was clear and considered: genetics are not fate.
The best evidence for that claim is also in the graph above. Among the people with the top 1% of polygenic risk for obesity, 30% are not obese. So, the obvious and important question is: Why not?
Adam explains that genes do not operate in a vacuum. A polygenic score measures only some of the biological pressure pushing someone towards a higher BMI. Whether that pressure becomes actual fact still depends on a person’s diet, physical activity, socioeconomic circumstances, and their wider food-environment.
The most interesting research taking place, in my view, is in looking at people who have a high Polygenic Risk Scores but don’t have obesity. That minority of people can help us understand how genetic risks can be mitigated and which interventions work best.
2. Genetics as demographic data
Polygenic Risk Scores attempt to predict someone’s susceptibility to developing obesity, but Adam’s latest research asks a much more commercially interesting question: can genetics help predict what happens once that person starts GLP-1 treatment?
Pharma companies are already combing through the latest genetic research looking for ways to better define their drugs’ target demographics. As the weight-loss market becomes increasingly crowded, differentiation will become harder. If you’re a manufacturer with a new amylin drug that acts on a different genetic receptor than your competitors’ GLP-1s, who better to target than a population of patients who have a higher risk of side effects with GLP-1s due to their genetics?
For marketing purposes alone, genetics could give pharma companies a compelling answer to the question every new entrant is facing from Wall Street investors: Why should your drug exist in the market when a patient can buy generic semaglutide at half the price in the next few years?
Adam and his team surveyed 27,885 participants of a 23andMe study who had used semaglutide or tirzepatide. Of these, 15,237 had sufficient data for the primary weight-loss genetic analysis. The team scanned the patients’ genomes to see whether particular variants could help explain differences in weight loss and the severity of 11 self-reported side effects.
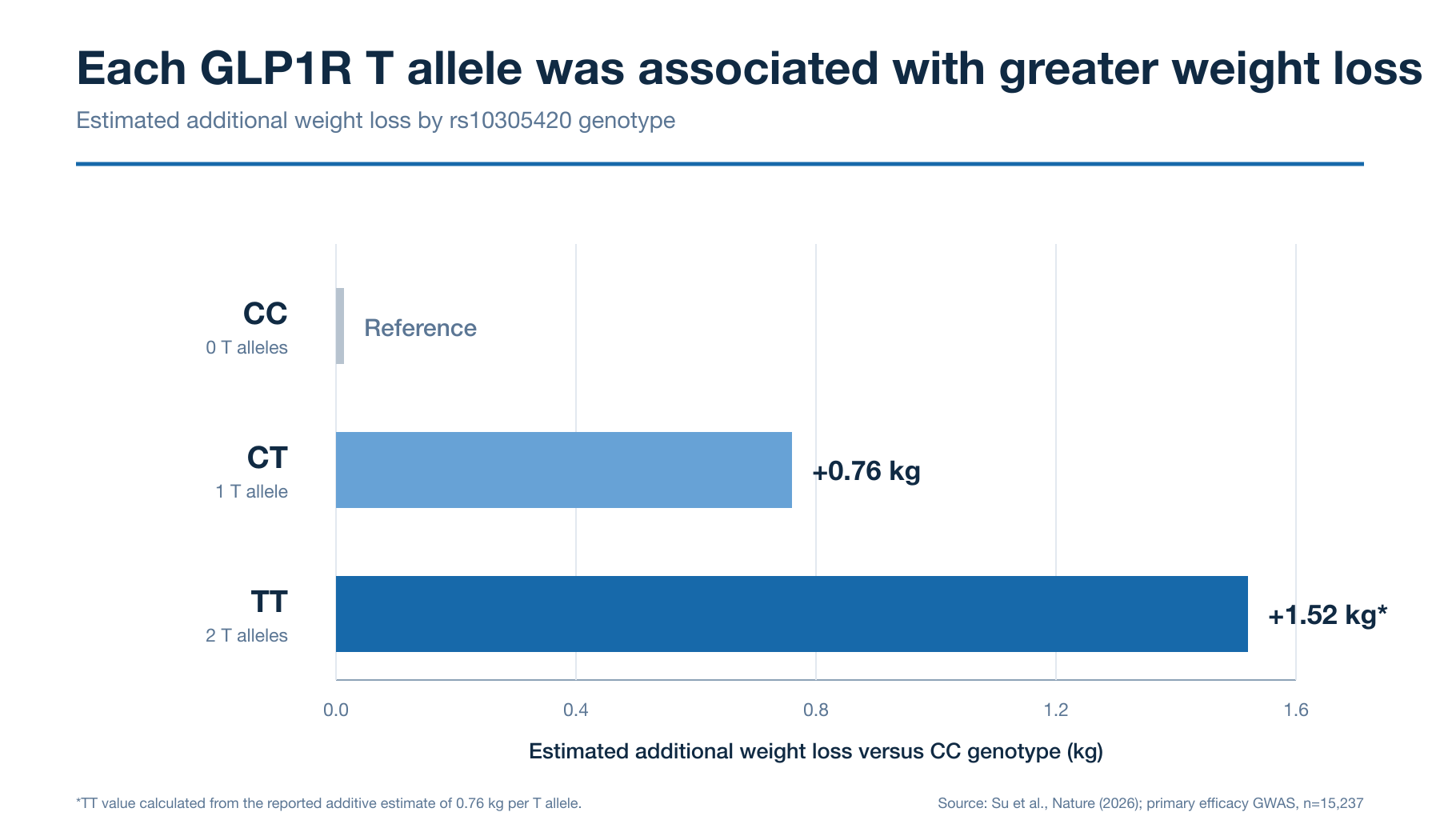
For weight loss, the strongest signal appeared in GLP1R, the gene encoding the receptor targeted by both semaglutide or tirzepatide. Each copy of the identified variant was associated with an additional 0.76 kilograms of weight loss, and because we inherit one copy from each parent, some people will therefore carry two copies, which is associated with approximately 1.5 kilograms of additional weight loss.
As Adam said, “We’re probably onto the right path.” Their study revealed that it’s likely genetic variations affect how well the GLP1R receptor reaches the cell surface.
One or two kilograms may sound small relative to the typical GLP-1 headlines you read. But Adam estimates that, for someone carrying two copies, the difference could represent around 10% of their expected weight loss which is, on reflection, significant.
Semaglutide activates the GLP-1 receptor, whereas tirzepatide activates both the GLP-1 and GIP receptors.I was surprised to learn that the study found no comparable link between GIPR variation and weight loss. Tirzepatide produces greater average weight loss, so its additional GIP activity is considered an important part of its advantage. I therefore expected variation in the GIP receptor gene to help explain why some patients lose more weight than others.
Adam was also surprised, and offered two explanations: either the particular GIPR variant genuinely does not affect weight loss, or the study did not include enough tirzepatide users to detect the effect.
Regardless, you can imagine using a patient’s genetics to identify which drugs they would respond best to, and this information would more precisely set their expectations and make them more willing to persist with treatment, which is a great way to boost retention (and adherence).
3. Predicting Side Effects and Setting Expectations
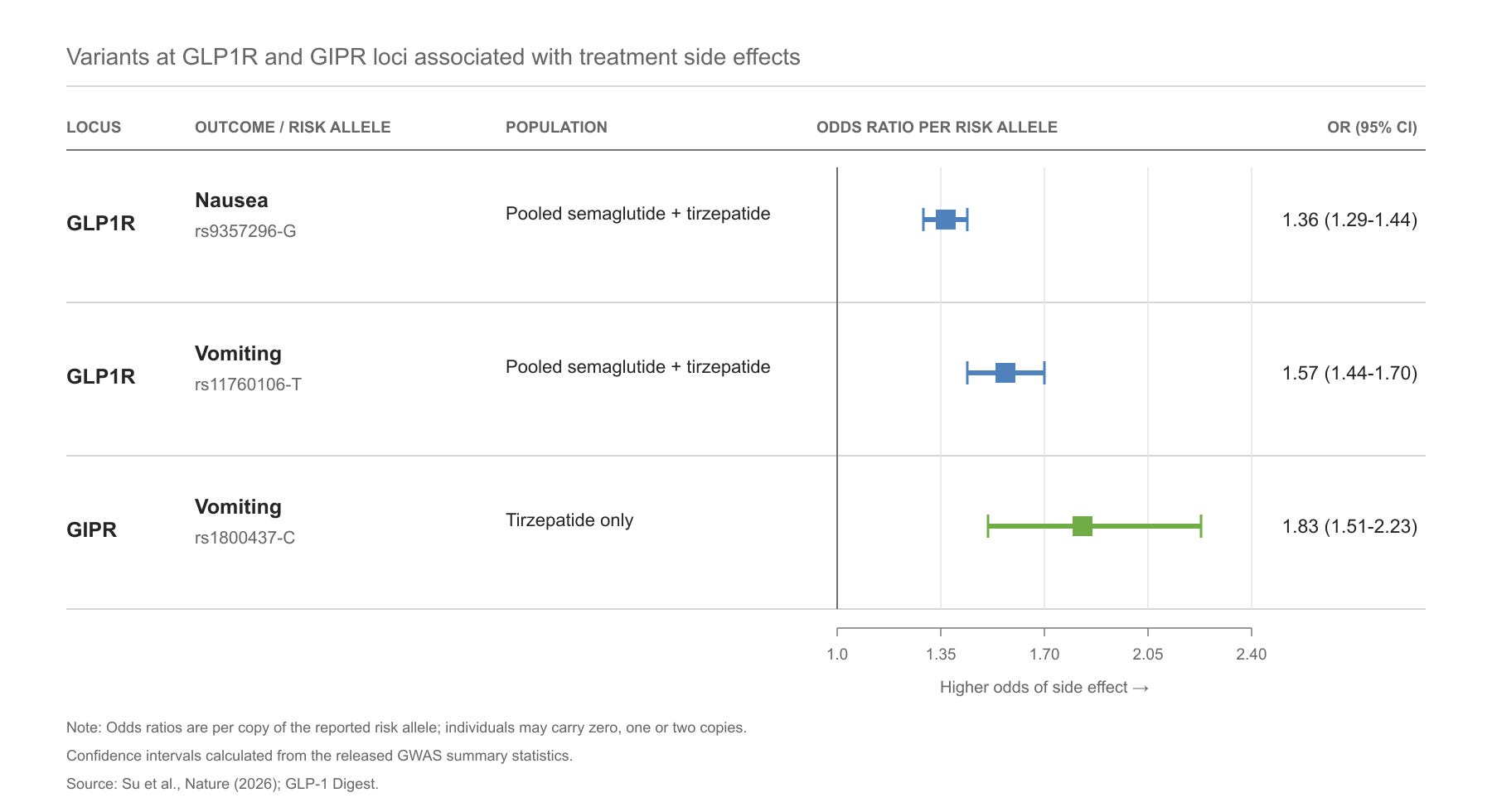
Adam and his team also looked at whether genetic variants could explain why some people experience more side effects than others. As he put it, the result was “very beautiful,” because the genetic signals appeared around the genes encoding the exact receptors targeted by the drugs.
For people taking GLP-1s, genetic variants around the GLP-1 receptor gene are associated with both nausea and vomiting. When researchers looked specifically at people taking tirzepatide, they found an additional variant in the GIP receptor gene. This was most strongly associated with vomiting.
The team then combined these genetic variants with other clinical information to predict who would experience side effects. The model achieved an area under curve (AUC) of 65.4% for nausea and 68% for vomiting. This means that if the model were shown two patients, one who experienced vomiting and one who did not, it would give the patient who experienced vomiting the higher predicted risk about 68% of the time.
For context, an AUC of 50% is no better than chance, and an AUC of 100% would separate the two groups perfectly. So, while the model detected a good signal, Adam said a score closer to 90% would begin to feel clinically decisive and useful.
As always, the most interesting result appeared at the extreme. People carrying two copies of both the GLP1R weight-loss variant and the GIPR vomiting-associated variant had an estimated 15-fold higher odds of tirzepatide-related vomiting than people carrying two non-risk copies at both locations.
This was a small group, and the estimate had a wide range of uncertainty. But we’re getting to a place where we may be able to identify a small number of people with an unusually high risk for certain side effects.
As Adam explained, simply knowing that nausea may be expected could reduce anxiety and make the treatment experience easier to manage.
You can also imagine how this could strengthen the case for more personalised titration schedules. If a patient is known to have a much higher genetic risk of nausea or vomiting, their D2C provider might eventually consider slower dose escalation, rather than forcing that patient through the same schedule as everyone else.
The evidence does not yet support changing doses based on genetics alone, as Adam stressed. But from a DTC perspective, the opportunity is clear as day.
**The views, opinions, and recommendations expressed in this essay are solely my own and do not represent the views, policies, or positions of any other organization with which I am affiliated. This content is provided for informational purposes only and should not be considered medical, legal or investment advice.**
